Sat Apr 15 2023 16:20:21 | Brought to you by Vercel and ChatGPT | It's been a while! Functionally, not much has changed - I did finish my mobile app for uploading, which works fine, and I added spotify integration. But under the hood, everything's different!
This website started as a lowest-possible-effort attempt to make a little interactive map that tracked my checkins. By the end, I had a custom Ruby script that would iterate over the files in a code repository to generate the HTML (and associated JS) for all checkins, peeps, and leaderboards. The output was then uploaded to S3 and served statically via Cloudfront. My backend consisted of Lambda functions fronted either by API Gateway or Cloudfront (via Lambda@Edge), and I used DynamoDB for storing a few things like live peep data and subscribers.
All in all it's a fine solution, but it probably wouldn't stand the test of time. I want to add user accounts and turn this into a platform for other people to create similar websites. (For fun, of course - if I get even just a couple people to try it out, I'll be happy!) Plus, becoming familiar with a modern high-abstraction full-stack platform would be a plus for future unrelated projects.
So what you're looking at today is a complete re-do! The website is now written with React and NextJS and hosted on Vercel, with a Supabase-hosted PostgreSQL DB. Media is still hosted in S3 + Cloudfront. Vercel handles the serverless functions automatically in the same monorepo as the website codebase. It's been a pain in the ass to make the transition, but I've learned a lot, and Vercel + Supabase are a joy to work with.
There's far too much technical detail to spell out here, so here's just a few key thoughts/ideas/lessons floating around in my skull:
-
Was it worth it? Complete rewrites are always sus. That one story about Netscape's huge mistake lives rent-free in my head. The mitigating factors here are: (1) it's small-ish; (2) it's a hobby project, so it's OK if it's part academic exercise; and (3) honestly it was pretty jank. I think the only case where the rewrite won't be worth the investment is if I end up not implementing more complicated functionality - but even then, I get improved rendering/loading, and I became familiar with NextJS, Vercel, and Supabase.
-
Do I regret the homebrew solution? Not at all. There's a wonderful blog post about personal projects that I can't find now, but it imparts two principles I keep in mind: (1) assume you'll only work on them for 2 weeks and plan accordingly; and (2) try not to combine building something new with learning something new. Either build a new thing with a framework you know, or build something familiar with a new framework. The cost of using a new framework or paradigm is usually underestimated. If I had started off with Vercel + Supabase, I would have been much more likely to quit. I'm glad I did the minimum amount of work possible to get my vision out the door.
-
How do I feel about the new stack? Great! I'm sure I'm biased because by now I've made my bed, but Vercel + Supabase have been nothing but fast, well-documented, easy to use - not to mention free. Since I made the decision to use them, there have been plenty of other options that seem interesting (like Svelte). But at some point you have to stick with what you chose or else you'll never ship.
- Vercel: they hired the people who made NextJS, iirc. Vercel is perfectly suited for a NextJS application, and they do a great job of seamlessly integrating with Github and Supabase. They'll automatically serve your NextJS application, including handling the SSR, and host your serverless functions. Everything is said to be super fast because it runs on their widely distributed edge network. We'll see about that. They've also got built-in visitor analytics and web vitals tracking. Plus you can run cron jobs, and they act as a DNS registrar... it does everything and looks slick while doing it. Would recommend.
- Supabase: Supabase is an open source Firebase alternative that is all in on PostgreSQL. They encourage and streamline the use of RLS (row level security) to allow your website to safely and directly query the database. Supa cool! They have first-class support for authentication, so adding user accounts to the website should be easy. And their libraries play well with Typescript - there's even a built-in command to generate types from the database schema. My only gripe is that I don't really like learning an ORM's mangled version of SQL - I'd much prefer to write the SQL myself. Aside from creating a view in the database and querying that directly, Supabase doesn't have great support for writing your own SQL from the calling application. It's been fine so far though.
- Alternatives considered: I thought about using Elm instead, given how much I love writing Elm code. Ultimately I decided on taking a road more traveled as a safer option. But I plan on using Elm again in the future - it's such a joy to use.
-
Rewrites take so damn long! Yes they fucking do. Think hard before you embark on another one.
-
ChatGPT has been a big help especially when there's a minor but annoyingly complicated feature, or particularly devious bug. Prompting is a skill!
-
What's next? Well, I've got a few minor bugs to sort out. Once that's done, I'll hit the drawing board and start deciding how to make whereisjohndoe.com possible. Of course, who knows if it'll actually happen. That's the beauty - and the downside - of hobby projects.
ChatGPT told me to celebrate with a nice meal or dessert. I think it's not supposed to tell you to have a drink. I'll assume that's what it meant.
Wed Mar 17 2021 22:48PM | Move to Mobile | I'm sure you've noticed the /peepers tab. I didn't cover it with a devlog entry but to be fair it was a fairly simple implementation. It's always fun to write simple little algorithms like the one used to determine who has the longest streak.
The next big thing I'm cooking up isn't very user facing. One of my main issues with this website as a user is that posting checkins can be a bit of a pain. I've been doing so via a little bare-bones webform into which I had to manually punch in my AWS credentials - yikes! The image selection process is also cumbersome and doesn't allow for rearranging or organizing them at will - plus the fact that it's a webpage means that if I accidentally swipe the wrong way I'll refresh the page and lose everything I typed! Which is pretty annoying if I'm doing one of my wordier posts.
So I decided to move my checkin tool to a mobile app. While not strictly necessary for most of the improvements I want, a mobile app will allow me to implement some cool features down the road that require running in the background. And while I'm at it, I figured it was the right time to hook into Cognito for proper user credentials (I KNOW I KNOW I SHOULD'VE DONE THIS FOREVER AGO), and use AWS API Gateway to abstract checkin upload logic as opposed to manually pushing checkins to the database from the client.
Yup. I'm raising the bar up from "just get the job done" to "I don't want to lose track when enumerating the corners I cut".
Part of this is due to the fact that I've been considering keeping this website around for the long run. Even after I've stopped being a digital nomad bum, I think it'll be fun to create a new chapter every once in a while to track a weekend trip or a long vacation. Also, I think it'd be nice to have something technical to show potential employers to account for my extended time off, so I'm going to make sure I keep the bar high from now on.
Side note: I read a blog entry about how easy it was to hack an AWS account due to misconfigured Cognito and overly permissive Lambdas... and it scared me straight. Now I only grant resources the absolute bare minimum permissions they need to function, down to the target resource ARN.
Wed Jan 6 2021 3:04PM | Dynamic static peeps | Alright! So, I took a bit of a risk by implementing Ivan's idea of keeping only the open peeps dynamic and all the claimed peeps static (I should mention, he only briefly mentioned this idea in passing and wasn't necessarily giving it his stamp of approval).
For the non-technically inclined that venture into the devlog (you're welcome here too!), here's what I mean with these keywords. "Static" website content loosely means content that doesn't change very often (blog posts are the classic example). As such, its HTML is usually rendered beforehand, and handed to the client - aka your browser - immediately after the request for the website is made. So if this website were entirely static, this would be the chain of events:
- browser requests data from whereisdavidaugustus.com
- server responds with HTML/CSS/JS representing the entire website
- browser can render that HTML immediately with no further requests needed (except separate requests for images, videos, assets, and services like Google maps)
With "dynamic" content, what happens instead is this:
- browser requests data from whereisdavidaugustus.com
- server responds with HTML/CSS/JS represting most of the website, but not the dynamic content (like checkins or peeps for example)
- the JS that the client just acquired requests data from a different endpoint (for example, whereisdavidaugustus.com/peep)
- the server behind that endpoint responds with data (for example JSON) representing the peeps
- the JS then generates HTML on the fly given that data
- the JS sticks that generated HTML into the appropriate place in the existing website
Why would we ever follow the second pattern? Tons of reasons. We might need to customize content for each user, or we might need to show stuff that changes very often. We might want to allow the user to page through data without having to refresh the entire page.
In the peep case, we need the peeper to update quickly and accurately! And yet, once a peeper is locked in, that name doesn't change. So I decided to take advantage of that and leave open peeps dynamic (the website will send a request to the backend database to make sure it's open) and claimed peeps static (the website will already include the HTML representing claimed peeps, and save the browser the trouble of having to check again with the database).
In the backend, I keep a DynamoDB database up-to-date with all existing peeps. When a new peep gets claimed, the main peep lambda updates the entry in the database, and asynchronously (without waiting for completion) calls a second lambda that replicates this peep in the static content repo used to build the website. No big deal if this lambda fails - it's not doing anything super important (no customer impact except for saving a little bandwidth). I'm not particularly thrilled about having peep data stored in two different places as this violates the single source of truth principle, but it was sort of inevitable given that I needed a data store accessible at build time, and using a code repo as a database felt... wrong. But IDK. I'm open to suggestions. Let me know what I did wrong!
Tue Dec 15 2020 19:32PM | Amazon and Google sent me angry emails | From the start of this project, one of my biggest objectives was keeping this website loading as fast as possible. It was originally designed as a low-key SPA (single page application) that would fetch checkins from the backend and render them in the browser. As the number of checkins grew it became obvious that some pre-rendering would be needed if I really wanted to keep it crispy - so I've had a wonderful time in the last few days re-architecting this thing into a mostly static website.
I finally uploaded my source code to GitHub. Link below. Big oops though: my git commit history apparently contains my AWS Access Key and Google Maps API Key in plaintext?? Weird, someone must've snuck in at night and committed those. AWS and Google both let me know via email that I needed to rotate those creds as soon as I could. Hey it's good to know they're scraping GitHub and looking out for you!
Some bullet points to keep it digestible:
-
I created stronger separations between my source code and content. Images and videos have their own directory on my local machine and go into their own S3 bucket. I used distribution behaviors in CloudFront to make sure the same distribution fronts both the website source and its content.
-
Giulio was right, you learn the most by just messing around with the AWS console. I took a nosedive approach to AWS CodePipeline and do not regret it. Pushing code to my main GitHub branch triggers a build and a deploy.
-
My build step runs a simple Rakefile that uses ERB (embedded Ruby) to template the source files (index.html.erb most notably). Did you know ERB is part of the Ruby standard library???
-
TODO: Get peeps working again. Since the website is now static, triggering a peep doesn't do much. Ivan's idea of keeping only the latest open peep dynamic and statically generating the HTML for all claimed peeps is a good one. I still need some creative thinking to make peeps seem quick and seamless though. Might have to use HTML local storage, aka fancy cookies.
Speaking of, I'm hungry. And I didn't get a wink of sleep.
Fri Oct 30 2020 13:27PM | Backfilling image dimensions | I thought my days of running backfill scripts were over. Today I wrote some Ruby to grab the dimensions of every checkin image and augment the checkin JSON with those dimensions. This is needed because if you don't set width and height of the image tag before it fully loads, the page won't preallocate the right amount of room for each image. So if the user scrolls down past the images while they are still loading, the page will appear to flicker as the HTML updates the sizes of the img tags.
I wasn't planning on fixing this bug yet but since I'm planning on pushing some features that require a consistent scrolling experience, the priority got bumped.
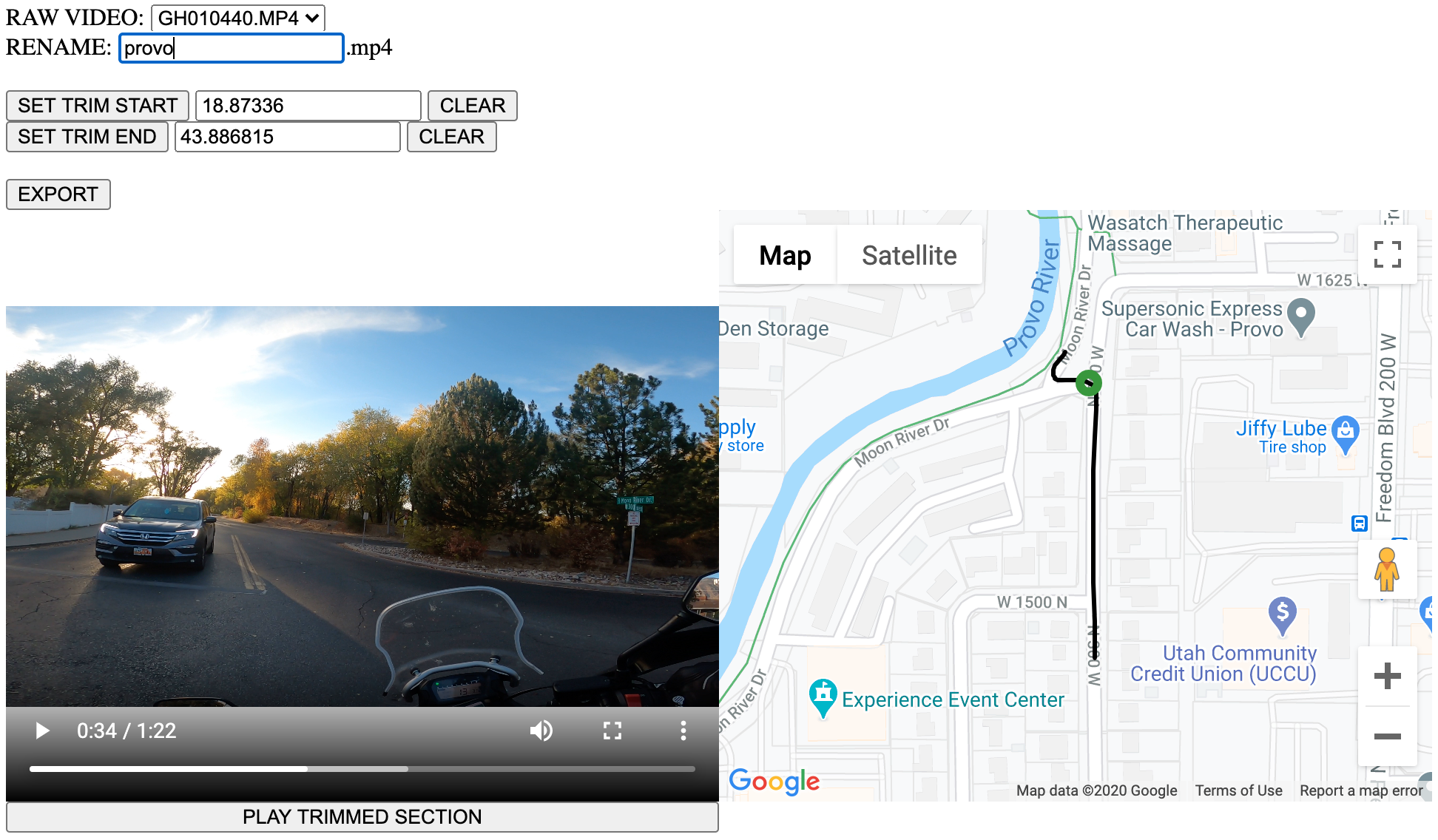
Thu Oct 29 2020 22:14PM | GoPro video and GPS data trimming | My ultimate goal with this feature is to be able to display a GoPro video within a checkin, while the map on the left displays the video's route and an icon that follows along the route in step with the video (basically like an aerial view). I've made some significant steps and have a working prototype, but there are a few more hurdles and design decisions to make before this thing is just the way I want it.
TL;DR: GoPros since the Hero5 sample GPS coordinates multiple times per second while recording. This GPS data, alongside a lot of other telemetry, is encoded as a track within the MP4 files alongside the video and audio streams, in a format called GPMF (GoPro Metadata Format). Which is super cool! A combination of two open-source tools (gpmf-extract and gopro-telemetry) allow you to extract and export the data automatically as GeoJSON, from which you can easily read the lat/lng coordinates array, match them with their corresponding entries in the relative milliseconds array (it's called RelativeMicroSeconds, but it's lying), and voila - you have a route and a timeline for your icon to follow.
There is one big hurdle, and it's taken up a decent amount of time to solve to my satisfaction. If you trim any portion of the MP4 that has a GPMF track, the GPMF track becomes unreadle by the libraries I mentioned. It must be because of whatever compression algorithm is being used. The obvious solution is to extract the coordinate data first and then trim both, but that would be super tedious to do manually for every GoPro video I want to trim, so obviously I stood up a local node express server with a simple front-end that lets me pick the trim start and end times, gives me a live preview, trims both the video and metadata, and makes it easy to attach them to a checkin. I'm just trying to enable my artistic side!
The Colorado River checkin (which, as of this writing, no one has peeped yet 👀) is the first example of this in action on the live website, though it doesn't have the moving icon yet. Zoom in on the location of the marker and you'll see the route taken by the video. Eventually I want to make that zoom automatic, and obviously I want that moving icon. There's a lot of design considerations to take into account with the automatic zoom, especially on mobile. That's a story for another devlog post.
Just for fun, here's what the server looks like:
Links:
Tue Oct 20 2020 21:24PM | Hello World | I'll add an entry here when I push a change or new feature. It's just meant to be a super simple way to share the technical side of what I'm doing. By the way, did you know that the length limit for peeper names has been increased to 40 chars?
Giulio Finestrali was the original peeper - among other things, he helped with AWS Lambda@Edge and fixing caching problems
Ivan Petkov is constantly checking this thing and giving me feedback - he even caught an XSS vuln and proved it by hacking my mainframe. He also holds the record for most peeps
Jake Jensen has since smashed Ivan's record, including a ridiculous penta peep streak
Ari Richtberg was a soundboard and focus mate as I was fixing caching problems and writing templating logic
Sam Posa aka Tham Potha aka Posa-san gets a shout out just because he asked for one